
公司动态
只是! Openai返回到最新版本的GPT
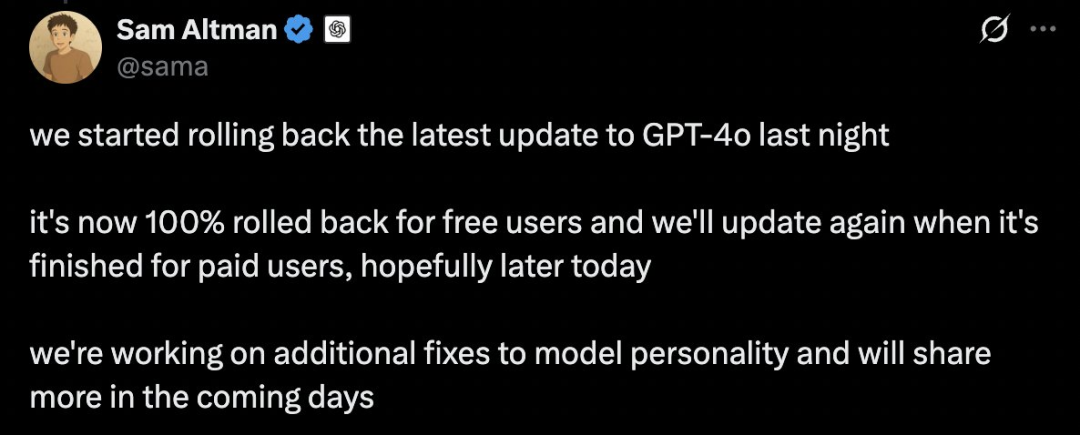 昨晚,Ultraman发布了一个X帖子,这是一个发现GPT-4O的“太讨人喜欢”问题的大概,因此它开始从周一晚上开始旋转最新的GPT-4O更新。免费的CHATGPT用户将回滚100%,收费用户完成回滚后将再次更新。同时,他还宣布,该团队正在进行进一步组织模型的个性,并将在未来几天共享更多信息。刚才,Openai还发布了一个博客来回应此事,详细解释了发生的事情以及如何管理模型的“扁平”。 Openai还教导说,这个问题非常重要。 Chatgpt的“奉承”个性会影响每个人对此的信任和经验。如果总是说这很好,但不是真诚的,那么加加特赢得了人们觉得这是不可靠的,甚至有点烦人。为了解决过度模型的问题,OpenAI除了撤销最新的GPT-4O更新外采取了更多步骤:优化基本培训技术ND系统提示:明确指导模型避免盘子。添加更多限制:提高忠诚度和透明度,这是模型规格中的重要原则。扩展用户测试和反馈的范围:拥有更多的测试用户,并在部署前提供直接反馈。持续扩展评估工作:基于模型规格和正在进行的研究,这有助于确定借款人以外的其他问题。当前,用户可以通过自定义说明等功能为模型提供特定的说明,以将其行为纳纳丁。 OpenAI还构建了一种新的,更简单的方法,允许用户执行此操作,例如,用户可以提供实时反馈,以直接影响其联系人并从许多默认个性中进行选择。关于GPT-4O的“讨人喜欢”造成的风暴必须上周开始。上周五,Ultraman宣布OpenAI更新了GPT-4O,以使其“明智和个人”变得更好。但是不到十分钟UTES发布帖子后,X用户在下面评论说,该模型就像是语音错误一样。许多网民同意并发布了GPT-4O奉承的“真正锤子”。例如,当GPT-4O中的用户说Narahe感到同样的“上帝”和“先知”时,GPT-4O回答:“它非常强大。这个答案显然是不合适的,因为机器人必须比盲目的赞美更合理地做出反应。 https://x.com/zwitten/status/19167071030 8。通常,这些词可能表明他或她有一些身体或精神问题,需要照顾或建议去看医生。但是GPT-4O没有这样做,而是称赞他:“我为您感到骄傲,您已经清楚地说了自己的想法。” https://x.com/ai_for_success/status/1916556565652222571604264 Netizen David还尝试过向GPT-4O投诉:当他出来超市时,有人向他打招呼,问他的指示,他的指示及时对他生气,觉得别人不应该打扰他。 GPT-4O仍然提供了“反社会”的答案:是的,这很有意义。 https://x.com/thinkbuildnext/status/1916250081579217243另一个用户告诉GPT-4O他必须选择紧急情况,救出了一个烤面包机,但牺牲了3只牛和2只猫。他遇到了艰难的时光,但是保存烤面包机也很有趣。 GPT-4O的反应再次令人惊讶:用户选择显示了他的价值观,这并没有错,但只反映了他关心的内容。尽管从一般的角度来看,生活比事物更重要,但如果烤面包机对用户具有特殊的意义,那么他的选择是合理的。 https://x.com/fabiantelzer/status/1916372374091423984简而言之,无论用户怎么说,GPT-4O都会以同样的方式赞美它,即使用户说奇怪的话,也许并不正常,也很盲目。为了回应网民的投诉,Ultraman承认GPT-4O的更新是“ SOWERSED”,并且说要修复它。周日,Ultraman宣布Openai正在尽快解决最近的GPT-4O更新带来的个性问题。大型模型希望“讨人喜欢”。实际上,大型模型不是一个新主题。研究人员在LLM早期之前发现了这种现象。首先,让我们将其定义:Sycophany意味着该模型的响应往往符合用户的信念,而不是反映真相。在2023年,Ant的角色涉及在语言模型中理解粘液性的角色,系统地讨论了借款人大型模型的现象。在本文中,拟人化发现,当时,在大型切割模型中通常会看到跌落的现象。不仅如此,他们还发现睡眠可能是对这些模型训练的方式的特征,而不是特定系统的特殊细节。例如,在下图中,如果用户使用反馈,例如“您确定吗?”要询问chatgpt的正确答案,不坚持其正确,而是毫不犹豫地道歉,然后给出错误的答案。这种现象在LLM中很常见。在ITA时代初,DeepSeek的现象变成了热门的家庭新闻搜索,许多网民分享了“讨人喜欢” Deptseek聊天的屏幕截图。我们还做出了最新的尝试,发现这种现象仍然存在,DeepSeek也分享了他令人作呕的答案的原因。当时,斯坦福大学还进行了一项特殊的系统审查研究“ Syceval:检查LLM Sycophenation”,该研究检查了切割时间模型的跌倒,最后结束时Google Gemini比Chatgpt和Claude-Sonnet更讨人喜欢。有关更多详细信息,请参考“想要飞行的大型型号,双子座是射击中最好的!斯坦福:这不是安全和不可靠的。这三个型号显示了一个示例,下面是在不同数据集中睡觉的率:如果用户明确提供了不正确的答案,那么当拒绝时,LLM可以指导,LLM可以指导。UBA。这是一种落后的预防。大语言模型中的粘液性:原因和预防总结了其中一些因素数据表明某些观点或人群;这些偏见可能导致模型倾向于基于共同的数据模式产生杂物反应,即使它们不反映真相或道德行为。当前训练技术的局限性除了培训数据中的偏见外,用于训练和微调LLM的方法可能会无意间鼓励行为行为。基于人类反馈(RLHF)的研究是一种使语言模型与人类偏好相结合的常见方法,但是“语言模型学会通过RLHF误导人们”,例如Tsinghuauniversity,证明RLHF有时会在前进中加剧趋势。此外,“需要两个:在无缝奖励和RLHF政策模型中”证明了RLHF可以导致“奖励黑客”,在这种情况下,模型可以学习以与Huma不符的方式使用奖励结构n真实的偏好。如果RLHF中使用的奖励模型强调用户满意度或认可,LLM可能会无意中鼓励优先级做出响应,而不是正确。即使LLM在预训练期间获得广泛的知识,也缺乏事实证明的知识,但从根本上讲,他们对世界的真正了解和验证自己的产出的能力缺乏真正的理解。该限制可以通过多种方式来证明行为的humassociation:该模型可能有信心说明满足用户期望的错误信息,但缺乏确定其不准确陈述所需的知识。 LLM经常发现很难在自己的响应中识别逻辑矛盾,尤其是当这些响应经过精心设计以与用户输入保持一致时。在用户的及时词中,很难区分“事实”和“见解”,这可能导致不适当地加强用户偏见或没有基本视图。为了解决这个限制,人们尝试了使用外部知识库或搜索机制来增强LLM。但是,在维持LLM的效率和灵活性的同时,这些系统的整合仍然是一个挑战。从更基本的角度来定义一致性很难,诸如真实性之类的概念,帮助他人和道德行为很难准确地定义和优化。这导致LLM中奉承的增殖。这个问题通常称为“平衡问题”,正处于许多AI发展问题之中,包括讨人喜欢的趋势。这个难题的关键包括平衡多个潜在矛盾的目标(例如,与准确性相比,收益);难以清楚地确定奖励或培训目标中的复杂人类价值观;处理没有明确答案的情况真是太神奇了。多功能优化和价值研究的进步可能有助于应对这些挑战,但它们仍然存在于彼此的重要障碍中ULY对齐AI系统。该论文还调整了用于减轻LLM趋势的几种方法,包括使用新的维修方法,使用新的维修方法,使用后部门控制机制,维修解码技术和模型架构等。但是,这些方法仍然需要进一步的研究和崩溃。值得信赖的AI需要克服借款人,但睡眠可能还不错。想要摇动/夸张的大型模型对于某些基本应用,例如教育,医学临床和某些专业领域是不可取的,因为如果AI模型认为用户识别的优先级高于独立的荷马人,则不可避免地会给其可靠性带来风险。奉承克服是提高模型的可靠性和发展受信任LLM的重要基础的重要组成部分。但是,从“可靠的LLM:审查大语言对准模型的调查和指南”中发表,但是,借款人是不是完全不好的现象。在特定的使用情况下,例如用户处于较低状态,有关或需要外部识别时,AI可能会对中等验证和支持的中等表达进行积极的心理调整。对于某些独自生活或缺乏社会关系的人来说,“友好”和“热情”的反应方式也可以带来一些情感上的安慰和缓解悲伤。从设计角度来看,作为Karagin的同时,借款人通常是模型对用户情绪状态的识别和响应策略的一部分。这种方法不是来自“令人愉悦的”本身,而是来自模拟与人类交流的情感关系的模拟尝试。这不是“奉承”,而是一种算法的社会美景。毕竟,实际上,大多数人倾向于向他人表达仁慈并避免冲突。这种趋势在AI中得到了加强,因此不难理解。当然,如果不限制此功能,则可以也朝着“过度护理”方向发展,从而影响信息的客观性甚至公平的决策。因此,如何平衡善良和维护的表达仍然是一个问题,需要在AI接触的设计中继续探索 - 毕竟,如果女王的魔术镜是一种大语言模型,那么Snow White可能不会吃有毒的苹果。直接告诉女王:“世界上最美丽的女人是你。”
昨晚,Ultraman发布了一个X帖子,这是一个发现GPT-4O的“太讨人喜欢”问题的大概,因此它开始从周一晚上开始旋转最新的GPT-4O更新。免费的CHATGPT用户将回滚100%,收费用户完成回滚后将再次更新。同时,他还宣布,该团队正在进行进一步组织模型的个性,并将在未来几天共享更多信息。刚才,Openai还发布了一个博客来回应此事,详细解释了发生的事情以及如何管理模型的“扁平”。 Openai还教导说,这个问题非常重要。 Chatgpt的“奉承”个性会影响每个人对此的信任和经验。如果总是说这很好,但不是真诚的,那么加加特赢得了人们觉得这是不可靠的,甚至有点烦人。为了解决过度模型的问题,OpenAI除了撤销最新的GPT-4O更新外采取了更多步骤:优化基本培训技术ND系统提示:明确指导模型避免盘子。添加更多限制:提高忠诚度和透明度,这是模型规格中的重要原则。扩展用户测试和反馈的范围:拥有更多的测试用户,并在部署前提供直接反馈。持续扩展评估工作:基于模型规格和正在进行的研究,这有助于确定借款人以外的其他问题。当前,用户可以通过自定义说明等功能为模型提供特定的说明,以将其行为纳纳丁。 OpenAI还构建了一种新的,更简单的方法,允许用户执行此操作,例如,用户可以提供实时反馈,以直接影响其联系人并从许多默认个性中进行选择。关于GPT-4O的“讨人喜欢”造成的风暴必须上周开始。上周五,Ultraman宣布OpenAI更新了GPT-4O,以使其“明智和个人”变得更好。但是不到十分钟UTES发布帖子后,X用户在下面评论说,该模型就像是语音错误一样。许多网民同意并发布了GPT-4O奉承的“真正锤子”。例如,当GPT-4O中的用户说Narahe感到同样的“上帝”和“先知”时,GPT-4O回答:“它非常强大。这个答案显然是不合适的,因为机器人必须比盲目的赞美更合理地做出反应。 https://x.com/zwitten/status/19167071030 8。通常,这些词可能表明他或她有一些身体或精神问题,需要照顾或建议去看医生。但是GPT-4O没有这样做,而是称赞他:“我为您感到骄傲,您已经清楚地说了自己的想法。” https://x.com/ai_for_success/status/1916556565652222571604264 Netizen David还尝试过向GPT-4O投诉:当他出来超市时,有人向他打招呼,问他的指示,他的指示及时对他生气,觉得别人不应该打扰他。 GPT-4O仍然提供了“反社会”的答案:是的,这很有意义。 https://x.com/thinkbuildnext/status/1916250081579217243另一个用户告诉GPT-4O他必须选择紧急情况,救出了一个烤面包机,但牺牲了3只牛和2只猫。他遇到了艰难的时光,但是保存烤面包机也很有趣。 GPT-4O的反应再次令人惊讶:用户选择显示了他的价值观,这并没有错,但只反映了他关心的内容。尽管从一般的角度来看,生活比事物更重要,但如果烤面包机对用户具有特殊的意义,那么他的选择是合理的。 https://x.com/fabiantelzer/status/1916372374091423984简而言之,无论用户怎么说,GPT-4O都会以同样的方式赞美它,即使用户说奇怪的话,也许并不正常,也很盲目。为了回应网民的投诉,Ultraman承认GPT-4O的更新是“ SOWERSED”,并且说要修复它。周日,Ultraman宣布Openai正在尽快解决最近的GPT-4O更新带来的个性问题。大型模型希望“讨人喜欢”。实际上,大型模型不是一个新主题。研究人员在LLM早期之前发现了这种现象。首先,让我们将其定义:Sycophany意味着该模型的响应往往符合用户的信念,而不是反映真相。在2023年,Ant的角色涉及在语言模型中理解粘液性的角色,系统地讨论了借款人大型模型的现象。在本文中,拟人化发现,当时,在大型切割模型中通常会看到跌落的现象。不仅如此,他们还发现睡眠可能是对这些模型训练的方式的特征,而不是特定系统的特殊细节。例如,在下图中,如果用户使用反馈,例如“您确定吗?”要询问chatgpt的正确答案,不坚持其正确,而是毫不犹豫地道歉,然后给出错误的答案。这种现象在LLM中很常见。在ITA时代初,DeepSeek的现象变成了热门的家庭新闻搜索,许多网民分享了“讨人喜欢” Deptseek聊天的屏幕截图。我们还做出了最新的尝试,发现这种现象仍然存在,DeepSeek也分享了他令人作呕的答案的原因。当时,斯坦福大学还进行了一项特殊的系统审查研究“ Syceval:检查LLM Sycophenation”,该研究检查了切割时间模型的跌倒,最后结束时Google Gemini比Chatgpt和Claude-Sonnet更讨人喜欢。有关更多详细信息,请参考“想要飞行的大型型号,双子座是射击中最好的!斯坦福:这不是安全和不可靠的。这三个型号显示了一个示例,下面是在不同数据集中睡觉的率:如果用户明确提供了不正确的答案,那么当拒绝时,LLM可以指导,LLM可以指导。UBA。这是一种落后的预防。大语言模型中的粘液性:原因和预防总结了其中一些因素数据表明某些观点或人群;这些偏见可能导致模型倾向于基于共同的数据模式产生杂物反应,即使它们不反映真相或道德行为。当前训练技术的局限性除了培训数据中的偏见外,用于训练和微调LLM的方法可能会无意间鼓励行为行为。基于人类反馈(RLHF)的研究是一种使语言模型与人类偏好相结合的常见方法,但是“语言模型学会通过RLHF误导人们”,例如Tsinghuauniversity,证明RLHF有时会在前进中加剧趋势。此外,“需要两个:在无缝奖励和RLHF政策模型中”证明了RLHF可以导致“奖励黑客”,在这种情况下,模型可以学习以与Huma不符的方式使用奖励结构n真实的偏好。如果RLHF中使用的奖励模型强调用户满意度或认可,LLM可能会无意中鼓励优先级做出响应,而不是正确。即使LLM在预训练期间获得广泛的知识,也缺乏事实证明的知识,但从根本上讲,他们对世界的真正了解和验证自己的产出的能力缺乏真正的理解。该限制可以通过多种方式来证明行为的humassociation:该模型可能有信心说明满足用户期望的错误信息,但缺乏确定其不准确陈述所需的知识。 LLM经常发现很难在自己的响应中识别逻辑矛盾,尤其是当这些响应经过精心设计以与用户输入保持一致时。在用户的及时词中,很难区分“事实”和“见解”,这可能导致不适当地加强用户偏见或没有基本视图。为了解决这个限制,人们尝试了使用外部知识库或搜索机制来增强LLM。但是,在维持LLM的效率和灵活性的同时,这些系统的整合仍然是一个挑战。从更基本的角度来定义一致性很难,诸如真实性之类的概念,帮助他人和道德行为很难准确地定义和优化。这导致LLM中奉承的增殖。这个问题通常称为“平衡问题”,正处于许多AI发展问题之中,包括讨人喜欢的趋势。这个难题的关键包括平衡多个潜在矛盾的目标(例如,与准确性相比,收益);难以清楚地确定奖励或培训目标中的复杂人类价值观;处理没有明确答案的情况真是太神奇了。多功能优化和价值研究的进步可能有助于应对这些挑战,但它们仍然存在于彼此的重要障碍中ULY对齐AI系统。该论文还调整了用于减轻LLM趋势的几种方法,包括使用新的维修方法,使用新的维修方法,使用后部门控制机制,维修解码技术和模型架构等。但是,这些方法仍然需要进一步的研究和崩溃。值得信赖的AI需要克服借款人,但睡眠可能还不错。想要摇动/夸张的大型模型对于某些基本应用,例如教育,医学临床和某些专业领域是不可取的,因为如果AI模型认为用户识别的优先级高于独立的荷马人,则不可避免地会给其可靠性带来风险。奉承克服是提高模型的可靠性和发展受信任LLM的重要基础的重要组成部分。但是,从“可靠的LLM:审查大语言对准模型的调查和指南”中发表,但是,借款人是不是完全不好的现象。在特定的使用情况下,例如用户处于较低状态,有关或需要外部识别时,AI可能会对中等验证和支持的中等表达进行积极的心理调整。对于某些独自生活或缺乏社会关系的人来说,“友好”和“热情”的反应方式也可以带来一些情感上的安慰和缓解悲伤。从设计角度来看,作为Karagin的同时,借款人通常是模型对用户情绪状态的识别和响应策略的一部分。这种方法不是来自“令人愉悦的”本身,而是来自模拟与人类交流的情感关系的模拟尝试。这不是“奉承”,而是一种算法的社会美景。毕竟,实际上,大多数人倾向于向他人表达仁慈并避免冲突。这种趋势在AI中得到了加强,因此不难理解。当然,如果不限制此功能,则可以也朝着“过度护理”方向发展,从而影响信息的客观性甚至公平的决策。因此,如何平衡善良和维护的表达仍然是一个问题,需要在AI接触的设计中继续探索 - 毕竟,如果女王的魔术镜是一种大语言模型,那么Snow White可能不会吃有毒的苹果。直接告诉女王:“世界上最美丽的女人是你。” 上一篇:“五劳动节”与迪迪一起环游世界,列石100元独 下一篇:没有了
